https://arxiv.org/pdf/1801.01671.pdf
https://github.com/jiangxiluning/FOTS.PyTorch
GitHub - jiangxiluning/FOTS.PyTorch: FOTS Pytorch Implementation
FOTS Pytorch Implementation. Contribute to jiangxiluning/FOTS.PyTorch development by creating an account on GitHub.
github.com
0. Abstract
- FOTS : detection & recognition -->simultaneous & complementary ( computational&visual information 공유)
1. Introduction
- Common Method
- CNN : extract feature map
- another decoder : decode the regions ---> heavy time cost & ignore correlation [Background]
- FOTS
- learns more generic features -> shared between 'detection' & 'recognition'
- single detection network ---> computational cost ↓
- HOW? ROIRotate

- oriented detection bounding box에 따라, feature map으로부터 적절한 feature 가져옴
- text detection branch : predict the detection bounding boxes
- text proposal features
- RoIRotate : detection results에 따라 text propsal features 추출
- RNN encoder
- CTC(Connectionist Temporal Classification) decoder
2. Related Work
2.1. Text Detection
- character based methods (text를 character의 결합으로 생각)
- localize characters ----> group them into words or text lines
- Sliding-window-based methods
- connected-components based methods
- Recently
- AIM : directly detect words in images
- . . .
2.2. Text Recognition
- AIM : decode 'a sequence of label' from regularly cropped but variable-length text images
- Recently
- word classification based
- sequence-to-label decode based
- sequence-to-sequence model based
2.3. Text Spotting
- separate detection / recognition model
- Recently <Towards end-to-end text spotting with convolutional recurrent neural networks>
- detection : text proposal network inspired by RPN
- recogniton : LSTM with attention mechanism
- --> FOTS : 수직회전외의 더 복잡한 케이스 처리가능 + 빠름
3. Methodology
3.1. Overall Architecture
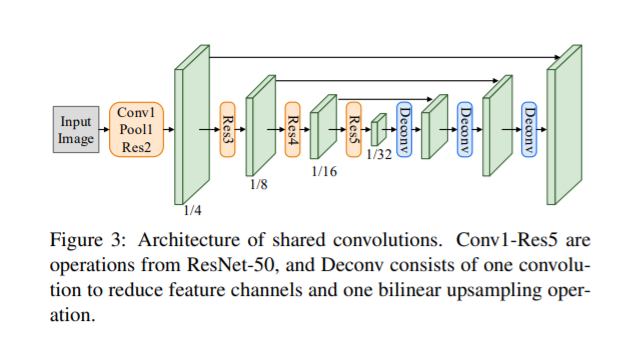
- backbone : ResNet-50
- concatenate -> low-level feature maps & high-level semantic feature maps
- text detection branch
- RoIRotate
- text detection branch 의 output = 'oriented text region proposals' 에 따라
- fixed-height representations로
- text recognition branch
- CNN and LSTM : encode text sequence information
- CTC : decode
3.2. Text Detection Branch
- text detector : fully convolutional network
- upscale the feature maps from 1/32 to 1/4 size
- first channel : the probability of each pixel being a positive sample
- positive sample?
- 4 channels --> predict its distances to top, bottom, left, right sides of the bounding box
- boundig box에 thresholding and NMS적용한 것 = final output
- positive sample?
- loss :

- text classification term
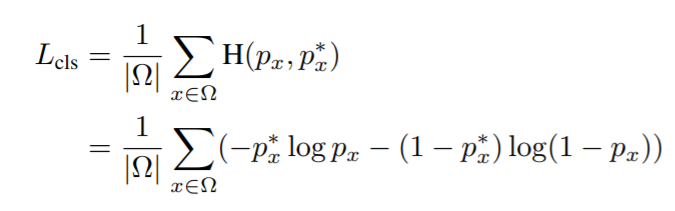
- bounding box regression term
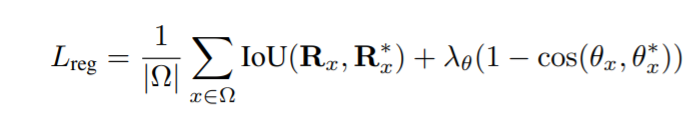
- text classification term
3.3. RoIRotate
- oriented feature regions ---> axis-aligned feature maps
- 원본이미지 그대로X, feature map을!
- (비뚤어진 글씨들 각도 맞게)

- 기존방식(ROI POOLING, ROI ALIGN)에 대한 차별점
- Bilinear Interpolation (이중 선형 보간법)활용 -> 출력길이 가변적
- *이중선형보간법 : x축, y축으로 선형보간법 두번적용
- Importance
- text recognition은 noise에 매우 예민
3.4. Text Recognition Branch
- Aim : predict text labels ( RoIRotate에서 얻은 region features 활용해서 )
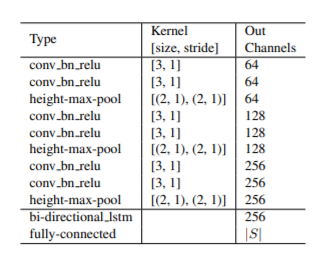
- VGGlike sequential convolutions
- poolings with reduction along height axis only
- output : higher-level feature maps
- encoder : bi-directional LSTM
- one fully-connection
- decoder : CTC ( frame-wise classification scores ---[transform]---> label sequence )
- Loss

'Paper > OCR' 카테고리의 다른 글
| [OCR] ViT-STR: Vision Transformer for Fast and Efficient SceneText Recognition (0) | 2022.02.03 |
|---|---|
| [OCR] Donut : Document Understanding Transformer without OCR (0) | 2022.01.25 |
| [OCR] TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models (0) | 2022.01.23 |
| [Search] OCR (0) | 2022.01.18 |

