https://arxiv.org/pdf/2105.08582.pdf
https://github.com/roatienza/deep-text-recognition-benchmark
GitHub - roatienza/deep-text-recognition-benchmark: PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficien
PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficient Scene Text Recognition (ViTSTR) - GitHub - roatienza/deep-text-recognition-benchmark: PyTorch code of my ICDAR 2021 pap...
github.com
0. Abstract
- STR (Scene test recognition)
- Recognition Model
- 그동안 accuracy에 비해 주목받지 못했던 speed and computational efficiency에도 주목
1. Introduction
- 기존 OCR보다 more structured setting
- accuracy, speed, computational efficiency
- focus on text recognition of 96 Latin characters (i.e. 0-9, a-Z, etc.)
2. Related Work
- Rectification - Feature Extraction (Backbone) - Sequence Modelling - Prediction
- No-Recurrence sequence-to-sequence Text Recognizer (NRTR)
- Self-Attention Text Recognition Network (SATRN) ... 등의 transformer based model에 적용가능
- Rectification stage
- Role: Retificationstage -> distortion 제거
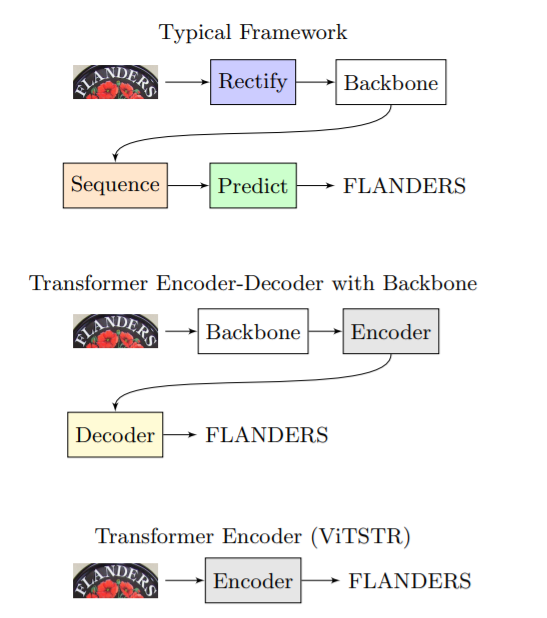
- Role: Retificationstage -> distortion 제거
- Feature Extraction (Backbone) stage
- Role: automatically determine the invariant features of each character symbol
- Rosetta, STAR-Net and TRBA : ResNet
- RARE and CRNN : VGG
- R2AM and GCRNN : RCNN
- NRTR and SATRN : customized CNN
- Sequence Modelling stage
- STR : a multi-class sequence prediction -> remember long-term dependency
- Role : 현재 단어와 미래, 과거 단어사이 일정만 문맥유지
- Prediction stage
- Role : examines the features resulting from the Backbone or Sequence modelling
- CTC (Connectionist Temporal Classification)
- maximizes the likelihood of an output sequence
- efficiently summing over all possible input-output sequence align
- Attetion
- learns the alignment between the image features and symbols
- CRNN, GRCNN, Rosetta and STAR-Net use CTC. R2AM, RARE and TRBA
3. Vision Transformer for STR : ViTSTR

- ViT + prediction head -> ViTSTR
- single object detection X
- identify multiple characters with the correct sequence order and length O
- predict in pararell
- 원래는 input : word vector, 그러나 이경우 image
- input image x ∈ R H×W×C ------> a sequence of flattened 2D patches x^p ∈ R N×P 2C
- H × W with C channels ------> P × P dim
- embedding
- 고정된 너비 D 이용, 이를 맞추기 위해 각 patch들 Linear Projection
- A learnable class embedding of the same dimension D ---> sequence
- resulting vector sum = encoder의 input
- encoding
- learnable position encoding
- original ViT : output vector corresponding to the learnable class embedding --> object category prediction
- = ViTSTR : [GO] token
- [GO] token : the beginning of the text prediction
- [s] token : end of each text prediction
- extract multiple feature vectors from the encoder (not one output vector)

one encoder block
- One Encoder Block
- LN
- MSA : determines the relationships between feature vectors
- MLP : feature extraction
- 2 layers with GELU activation

'Paper > OCR' 카테고리의 다른 글
| [OCR] FOTS: Fast Oriented Text Spotting with a Unified Network (0) | 2022.02.03 |
|---|---|
| [OCR] Donut : Document Understanding Transformer without OCR (0) | 2022.01.25 |
| [OCR] TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models (0) | 2022.01.23 |
| [Search] OCR (0) | 2022.01.18 |

