0. Abstract
catastrophic forgetting을 #incremental learning 을 통해 해결하고자 함.
전체 frame work 를 E2E으로 구성. 즉, data representation과 classifier를 jointly learn
CIFAR-100 , ImageNet을 통해 Evaluate 함.
1. Introduction
Main challenge : 현실에 적용하여 incremental하게 학습할 수 있는 classifier를 위한 / visual recognition system 구축
기존의 모델은 new data + old data 조금으로는 학습 불가능함. (시도는 있었으나 성능저하 극심했음.)
Incremental DL approach
- flow of data로 학습
- 기존+새로운 클라스에 대해 good classifying performace
- 합리적인 파라미터수 + 메모리
- classifier & feature representation 을 jointly learn할 수 있는 E2E learning mechanism
기존 그 어떤 연구도 네가지 조건을 모두 만족하지 못했음. 네가지 조건을 모두 만족하는 SOTA 모델 부재.
(decouple classifier, original data와 new data가 매우 유사, SVM과 같은 전통적 ML model에 국한 .. )
Main Contribution : Incremental Learning을 위한 E2E approach 를 소개
- 어떤 DL architecture에도 적용가능
- old dataset에 비해 규모가 작은 new sample에도 민감하게 변화하는 representative memory component
- cross-distilled loss
- cross entropy loss : 새로운 클라스 학습
- distillation : 기존 클라스에서 previous knowledge 얻음
- Image classification을 위한 접근법 - SOTA
2. Related Work
Traditional approach
- SVM에 집중
- 특정 classifier로 국한. (traditional approach은 SVM에 집중)
- representation 과 classifier 를 jointly 학습
- Lifelong learning / Never-ending learning
- Lifelong learning : origin task에서 얻은 knowledge를 new task로 transfer하는 데 집중
- Never-ending learning : 기존 classifier나 새로운 task를 학습하기 위해 연속적으로 데이터를 받는 것에 집중
- complete하지 않은 training set을 활용함으로서 일부 해결했지만, fixed(engineered) representation
- restrict classifier / regression model
- NMC(nearest mean classifier) or random forest variant
- Main drawback : task-specific data representation 부재
- 해당 모델은 이 단점을 feature & classifier jointly learning 을 통해 해결하고자 함.
Deep Learning approaches
Challenge : Incremental learning 은 catastrophic forgetting의 문제를 피하기 어려움.
- Initial approach : connectionist network 에 초점
- recent approach : old task 성능 보존을 위해 cross entropy loss와 distillation loss 모두 사용
Approach 1 : Distillation loss
- 원래 서로 다른 network 사이의 transfer를 위해 제안됨.
- forgetting 은 줄였으나, 두 dataset 이 다르고 confusion 이 적은 단순 시나리오에서만 적용 그 성능은 이상과 멈.
- weak representation of old classes 때문
- 새로운 class를 담은 데이터가 추가되는 sequential learning scenario에서는 치명적인 오류 보임.
Approach 2 : 기존 모델에서 일부 층을 freeze (=새로운 데이터에 대한 adaptability 제한)
- autoencoder를 통해 기존 task에 대한 knowledge 보존
- 마찬가지로, 제한된 task에 대해서만 evaluate됨.
- origin task & new task 에 대해 전혀 다른 dataset 사용 + obeject detection task
- general한 task에 활용되기에는 한계 존재함.
Approach 3 : # of layer 증가시켜 새로운 class에 대해 배우는 feature 증가
- tree-structured model을 키워서, 새로운 클라스 처리하도록
Main Drawback : # of param 급격히 증가 ( # of weight , task, new layers 의 증가와 함께 )
--> 이 논문의 모델은 최소한의 model size increase 만.
iCaRL (incremental learning approach)
- training classifier & data representation 가 decoupled
- combination of distillation and classification losses로 새로운 sample 들어왔을 때 data representation model을 업데이트함.
- (. + 이 논문의 모델은 과거 클라스의 샘플들 즉, data representative memory 까지 활용)
3. Our Model
- cross-distilled loss function을 활용하여 DNN을 train.
- 적용가능한 모델에게 특정한 특징을 요구하지 않기에, 대부분의 분류 모델에 적용할 수 있음.

본 논문의 Incremental model 구조 - #feature_extractor : set of logits 생성 (추후에 softmax함수를 통과하여 class score로 변환--> 이를 통해 classification )
- #loss_function : old class에서 얻은 knowledge를 유지하기 위해, representative memory 활용 (old calsses에 대해 가장 representative한 샘플들만 저장)
- 이후 augmentation & finetuning 시행을 통해 SOTA 달성

3.1. Representative memory
- 새로운 class나 sample이 추가되면, 선택된 가장 representative한 sample들을 저장
- class수와 상괸없이 K sample로 메모리 제한 걸어둠.
- (이에 따라 class 많아질수록 # of samples per class (n) 수는 적어짐, n = [ K/c ] )
- operation 1 : selection of new samples
- 해당 class 내 평균 sample로 부터의 거리를 기준으로, 하나의 class 내에서 sample의 sorted list 생성.
- sorting criterion은 random selection 등의 기법을 실험해본 후 선택됨.
- 상위 n개의 sample을 가장 representative한 sample로 select
- class 하나당 한번씩 selection 모두 시행
- 해당 class 내 평균 sample로 부터의 거리를 기준으로, 하나의 class 내에서 sample의 sorted list 생성.
- operation 2 : removing samples
- training process 이후에 새로운 class에 메모리를 할당하기 위해서 시행
- 각 class의 마지막 sample을 삭제하고, 새로운 class sample 추가.
3.2. Deep network
- Architecture
- feature extractor : 이미지를 feature vector로 변환
- classification layer : 마지막 fc layer -> set of logits 생성됨. 이를 통해 weight 업데이트 & loss 계산.
- framework
- 우선 non- incremental learning framework에서 classification을 위한 훈련 시작.
- 새로운 class 생기면 새로운 classification layer를 추가하고 연결.
(어떻게 파라미터 수 폭증 막을 수 있는지?) - incremental classification layer를 추가하고, cross-distilled loss를 활용하여 학습시키는 방식으로 진행하기 때문에, 어떤 모델에도 활용가능함.
- Cross-distilled loss function
- 두 loss를 combine
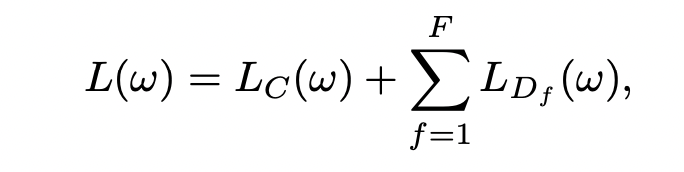
| distillation loss | old class의 knowledge를 포함 | old class에 해당하는 classification layer에만 적용 |
 |
|
| multi-class cross-entropy loss |
new class 학습에 활용 | 모든 classifiacation layer에 적용 |  |
|
4. Incremental Learning
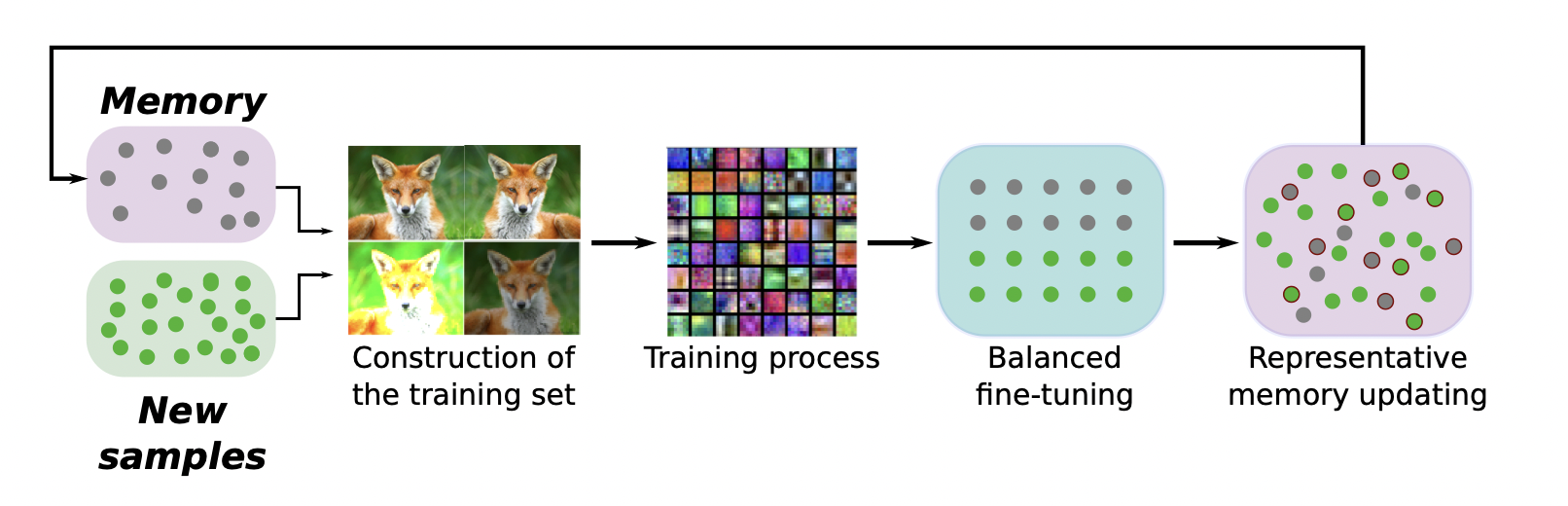
1st step : construction of training set
- training set -> 새로운 class의 sample + 기존 class의 exempler 로 이루어짐
- 1) classification 2) distillation 두 task를 위해 두 loss 사용하기 때문에, 각 sample에 대해 label 두가지 필요함.
- classification : 해당 이미지의 class를 의미하는 one-hot vector를 라벨값으로 활용
- distillation : old class에 대해 classification layer에서 만들어진 logit을 라벨값으로 활용
old knowledge를 강화하기 위해, 새로운 class의 sample들도 distillation에 활용
2nd step : training process
- augment된 training set을 활용
- feature extractor에서 뽑힌 feature는 incremental하게 모델이 업데이트되며 함께 변화함.
- 이에 맞추어 classification layers의 weight값들도 계속 변화 = 다른 모델들과의 차별점 (frozen,
classification layer만 학습... )
3rd step : Balanced finetuning
- : training set의 subset(representative memory) 을 활용하여 fine-tuning
- old class의 sample들을 직접 저장하는 것이 아님. 그래서 new class의 sample들에 비해 low할 수 있음
- 이를 해결하고자 additional new subset으로 fine-tuning
- 해당 class가 old인지 new인지 상관없이, 동일한 개수씩 sample 추출
- = 이는 new class의 sample을 앞에 언급했던 sort&select algorithm에 따라 적게 뽑는 것.
- 지난 training process에서 new class에 대해 학습한 내용 잊을 가능성 존재.
- 이를 방지하기 위해 새로운 classification layer에 temporary distillation loss 추가
4th step : Representative memory updating
- : representative memory가 새로운 class smaple을 포함하도록 update
- sorted class sample에서 일부 삭제
- -> 새로운 class를 위한 메모리 할당
- -> selection algorithm에 따라 sample 추가
